
迅雷链来鑫系列课程四|区块链的区块结构和持久化
发布日期:2025-04-15 来源:半岛官网登录入口网址
曾在百度参与建设分布式计算及网页搜索架构,后担任腾讯云高级工程师,主导去中心化负载均衡系统的大规模使用,以及分布式消息队列服务、信鸽移动推送、应用加固等多项研发技术。在分布式计算领域拥有丰富的经验。
2015 年加入迅雷,负责星域调度系统的研发技术,目前主导玩客云及区块链业务方案设计,建设共享计算的区块链底层平台。个人拥有分布式计算多项专利。

当前,区块链技术大红大紫,都说区块链是公开透明的,不可篡改的且不依赖信任节点的系统。
那么区块链的数据是如何存储的?区块链如何在没有中心信任节点的情况下,快速证明数据是可靠正确的?典型的智能合约中的数据在区块链上如何存取? 来鑫通过给出代码例子,用最通俗的语言,来阐释了这些的问题。
区块链是有序的向前引用的包含交易信息的区块列表。每个挖矿节点将交易打包放到区块中,然后分发到网络中以达成共识,也就是说,达成共识的最小单元是区块,而不是交易。其实若需要做成交易链也能的,但是达成共识的次数就数量级的提升了,这样区块链的性能将会大打折扣。
在持久化方面,区块链数据可以直接存储在一个扁平的文件中,也可以存储在简单的数据库系统中,比特币和以太坊都区块链数据存储在 google的 LevelDb中。
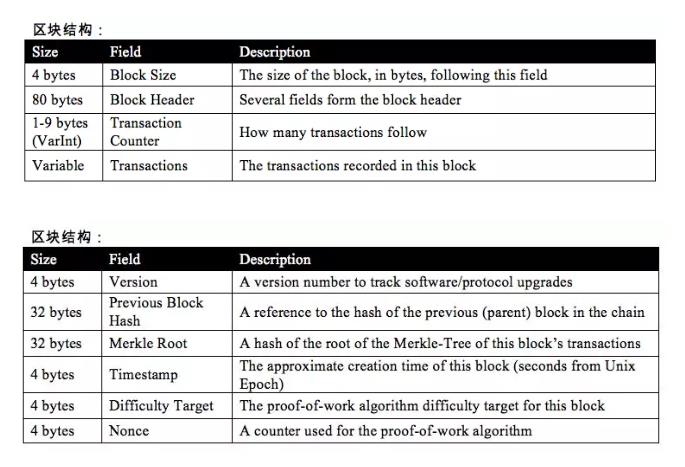
Version: 用于区分软件版本号Previous Block Hash:是指向前一个区块头的 hash。在比特币中,区块头的 hash一般都是临时算出,并没有包含在本区块头或者区块中,但在持久化的时候能作为索引存储以提高性能
Merkle Root: 是区块中所有交易的指纹,merkle tree的树根。交易在区块链节点之间传播,所有节点都按相同的算法(merkle tree)将交易组合起来,如此能判断交易是否完全一致,此外也用于轻量钱包中快速验证一个交易是不是真的存在于一个区块中。
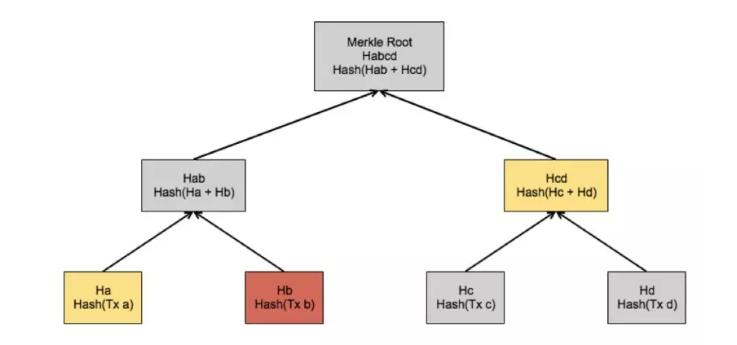
如上图,merkle Tree是一颗平衡树,树根也就是 Merkle Root存在区块头中。树的构建过程是递归地的计算 Hash的过程,如:先是 Hash交易 a得到 Ha,Hash交易 b得到 Hb,再 Hash前两个 Hash(也就是 Ha和 Hb)得到 Hab,其他节点也是同理递归,最终得到 Merkle Root。
1.仅仅看 merkle root就不难得知区块中的所有交易是不是一样的
2.对于轻量节点来说(不存储所有的交易信息,只同步区块头)提供了快速验证一个交易是不是真的存在交易中的方法。
merkle proof从某处出发向上遍历,算出 merkle Root的所需要经过的路径节点。在上图的例子中,如果轻量钱包要验证 Txb(红色方框)是不是已经包含在区块中,可以向全量节点请求 merkle Proof,用于证明 Txb的存在,过程为:
在上图的区块中,仅仅存在少量的区块。如果区块所包含的交易很多,merkle proof仅仅需要带 log2(N)个节点,此时 merkle proof的优势就会变得很明显。
在比特币中,系统底层不维护每个账户的余额,只有 UTXO(Unspent Transaction Outputs)。账户之间的转账通过交易完成,确切地说,比特币用户将 UTXO作为交易的输入,可以花掉一个或者多个 UTXO。
一个 UTXO像一张现金纸币,要么不使用,要么全部使用,而不能只花一部分。举个例子来说,一个用户有一个价值 1比特币的 UTXO,如果他想转账 0.5给某人,那他可以创建一个交易,以这个价值 1比特币的 UTXO为输入,另外产生 0.5比特币的 OTXO作为这个交易的输出(找零给自己)。
比特币这个公开底层系统本身不单独维护每个账户的余额,不过比特币钱包可以记录每个用户所拥有的 UTXO,这样计算出用户的余额。
以太坊相比比特币,额外引入了账号状态数据,比如 nonce、余额 balance和合约数据,这些是区块链的关键数据,具有以下特性:
随着交易的入块要一直高效地更新,所有的这一些数据在不同节点之间能够高效地验证是一致的,状态数据一直更新的过程中,历史版本的数据数据需要保留。
系统中的每个节点执行完相同区块和交易后,那么这些节点中对应的所有账户数据都是一样的,账户列表相同,账户对应的余额等数据也相同。总的来说,这些账户数据就像状态机的状态,每个节点执行相同区块后,达到的状态应该是完全一致的。但是,这个状态并不是直接写到区块里面,因为这一些数据都是可以由区块和交易重新产生的,如果写到区块里面会增加区块的大小,加重区块同步的负担。

tansaction root: 跟比特币中的 Merkle Root作用相同,相当于区块中交易的指纹,用于快速验 证交易是否相同以及证明某个交易的存在。
state root: 这颗树是账户状态(余额和 nonce等)存放的地方,除此之外,还保存着 storage root,也就是合约数据保存的地方。receipts root:区块中合约相关的交易输出的事件。
在 Transaction Root中,用类似比特币的二进制 merkle tree是能够处理问题的,因为它更适用于处理队列数据,一旦建好就不再修改。但是对于 state tree,情况就复杂多了,本质上来说,状态数据更像一个 map,包含着账号和账号状态的映射关系。除此之外,state tree还需要经常更新,经常插入或者删除,这样重新计算 Root的性能就显得尤其重要。
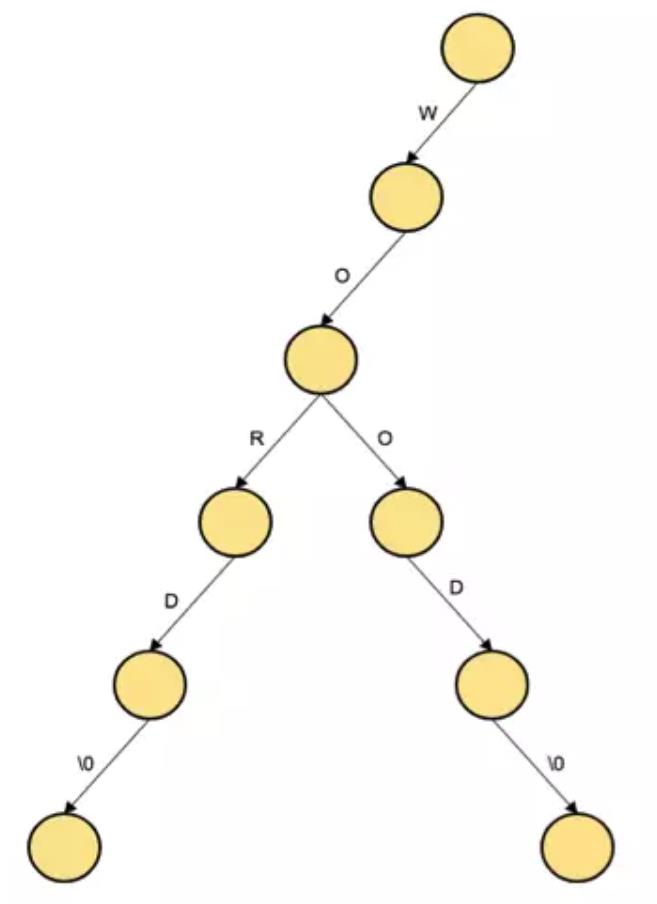
Trie是一种字典树,用于存储文本字符,并利用了单词之间共享前缀的特点,所以也叫做前缀树。Trie树在有一些时候是比较浪费空间的,如下所示,即使这颗树只有两个词,如果这两个词很长,那么这颗树的节点也会变得很多,无论是对于存储还是对于 cpu来说都是不可接受的。如下所示:
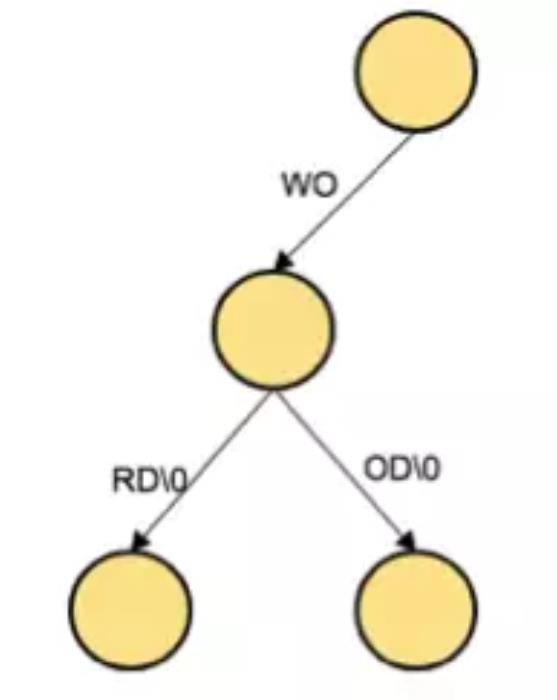
相比 Trie树,Patricia Trie将那些公共的的路径压缩以节约空间和提高效率,如下所示:
1.密码学安全,每个节点都都是按 hash引用,hash用来在 LevelDb中找对应的存储数据;
c.扩展节点,跟叶子节点类似,不过值变成了指向别的节点的 hash,[key, hash]
d.分支节点,是一个长度为 17的列表,前 16元素为可能的十六进制字符,最后一个元素为 value(如果这是 path的终点的话)
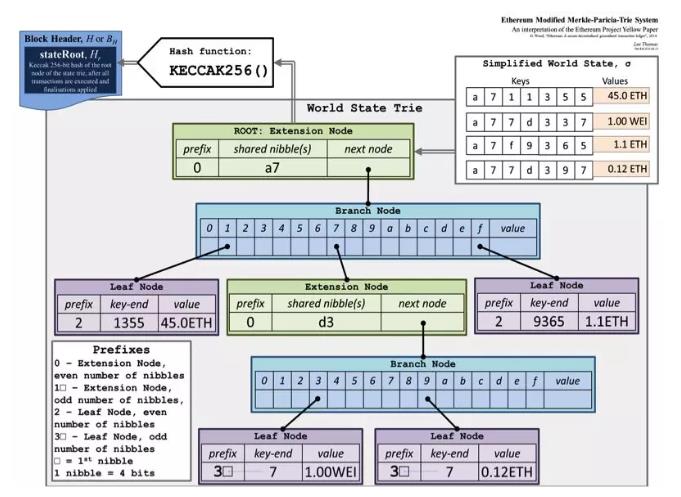
在上图中的 trie包含了 4对 key value,必须要格外注意的是,key是按照 16进制来显示的,也就是 a7占用一个字节,11占用一个字节等等
1.第一层的 Node是扩展节点,4个 Key都有公有的前缀 a7,next node指向一个分支节点
2.第二层是一个分支节点,由于 key转换成了十六进制,每个 branch最多有 16个分支。下标也作为 path的一部分用于 path查找。比如说下标为 1的元素中指向最左边的叶子节点(key-end为 1355),到叶子节点就完成了 key搜索:扩展节点中 a7 + 分支节点下标 1 + 叶子节点 1355 = a711355
3.叶子节点和扩展节点的区分。正如上面提到的,叶子节点和扩展节点都是两个字段的节点,也就是 [key,value],存储中没有专门字段用来标识类型。为了区分这两种节点类型并节约空间,在 key中加入了 4bits(1 nibble)的 flags的前缀,用 flags的倒数第二低的位指示是叶子节点还是扩展节点。此外,加入了 4bits之后,key的长度还有可能不是偶数个 nibble(存储中只能按字节存储),为此,如果 key是奇数个 nibble,在 flags nibble之后再添加一个空的 nibble,并且用 flags的最低位表示是否有添加,详见上图左下角。

下面将通过代码片段的形式,逐一验证各个 trie的结构(前提是先在本地搭建起以太坊私有链)。

在 trie包中写单测函数,key为交易在区块中的 index,RLP编码,value为签名过的原始交易 RawTransaction:
如下合约,为了简单起见,合约中省去了构造函数等不相关的内容,部署后地址为:
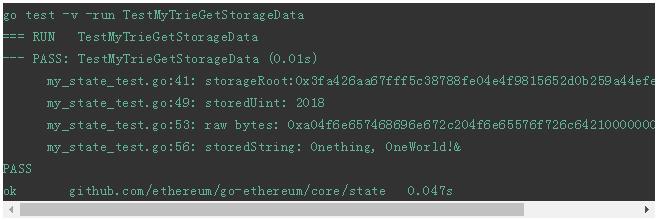
运行输出以下数据 storedUint为 2018,跟合约里的数据是一致的。有必要注意一下的是 storedString的数据后面多了一个十六进制的 26(十进制为 38),是字符串长度 (19)的两倍,更多的细节请参见 。
同时,更复杂的数据结构如变长数组、map等规则会更为复杂,同时这里也忽略了一些字段打包存储等细节,但是都围绕着 storageTrie,基础原理没有改变。
易能链与海通安恒达成战略合作 共建大数据+区块链企业数字化资产评级及投融资平台
HUAWEI Pura X 新机首销,华为浏览器每日早报让资讯“说”给你听
技嘉Z890钛雕主板以DDR5-12762MHz登顶内存超频之巅 重写性能天花板

迅雷链来鑫系列课程四|区块链的区块结构和持久化
发布日期:2025-04-15
曾在百度参与建设分布式计算及网页搜索架构,后担任腾讯云高级工程师,主导去中心化负载均衡系统的大规模使用,以及分布式消息队列服务、信鸽移动推送、应用加固等多项研发技术。在分布式计算领域拥有丰富的经验。
2015 年加入迅雷,负责星域调度系统的研发技术,目前主导玩客云及区块链业务方案设计,建设共享计算的区块链底层平台。个人拥有分布式计算多项专利。
当前,区块链技术大红大紫,都说区块链是公开透明的,不可篡改的且不依赖信任节点的系统。
那么区块链的数据是如何存储的?区块链如何在没有中心信任节点的情况下,快速证明数据是可靠正确的?典型的智能合约中的数据在区块链上如何存取? 来鑫通过给出代码例子,用最通俗的语言,来阐释了这些的问题。
区块链是有序的向前引用的包含交易信息的区块列表。每个挖矿节点将交易打包放到区块中,然后分发到网络中以达成共识,也就是说,达成共识的最小单元是区块,而不是交易。其实若需要做成交易链也能的,但是达成共识的次数就数量级的提升了,这样区块链的性能将会大打折扣。
在持久化方面,区块链数据可以直接存储在一个扁平的文件中,也可以存储在简单的数据库系统中,比特币和以太坊都区块链数据存储在 google的 LevelDb中。
Version: 用于区分软件版本号Previous Block Hash:是指向前一个区块头的 hash。在比特币中,区块头的 hash一般都是临时算出,并没有包含在本区块头或者区块中,但在持久化的时候能作为索引存储以提高性能
Merkle Root: 是区块中所有交易的指纹,merkle tree的树根。交易在区块链节点之间传播,所有节点都按相同的算法(merkle tree)将交易组合起来,如此能判断交易是否完全一致,此外也用于轻量钱包中快速验证一个交易是不是真的存在于一个区块中。
如上图,merkle Tree是一颗平衡树,树根也就是 Merkle Root存在区块头中。树的构建过程是递归地的计算 Hash的过程,如:先是 Hash交易 a得到 Ha,Hash交易 b得到 Hb,再 Hash前两个 Hash(也就是 Ha和 Hb)得到 Hab,其他节点也是同理递归,最终得到 Merkle Root。
1.仅仅看 merkle root就不难得知区块中的所有交易是不是一样的
2.对于轻量节点来说(不存储所有的交易信息,只同步区块头)提供了快速验证一个交易是不是真的存在交易中的方法。
merkle proof从某处出发向上遍历,算出 merkle Root的所需要经过的路径节点。在上图的例子中,如果轻量钱包要验证 Txb(红色方框)是不是已经包含在区块中,可以向全量节点请求 merkle Proof,用于证明 Txb的存在,过程为:
在上图的区块中,仅仅存在少量的区块。如果区块所包含的交易很多,merkle proof仅仅需要带 log2(N)个节点,此时 merkle proof的优势就会变得很明显。
在比特币中,系统底层不维护每个账户的余额,只有 UTXO(Unspent Transaction Outputs)。账户之间的转账通过交易完成,确切地说,比特币用户将 UTXO作为交易的输入,可以花掉一个或者多个 UTXO。
一个 UTXO像一张现金纸币,要么不使用,要么全部使用,而不能只花一部分。举个例子来说,一个用户有一个价值 1比特币的 UTXO,如果他想转账 0.5给某人,那他可以创建一个交易,以这个价值 1比特币的 UTXO为输入,另外产生 0.5比特币的 OTXO作为这个交易的输出(找零给自己)。
比特币这个公开底层系统本身不单独维护每个账户的余额,不过比特币钱包可以记录每个用户所拥有的 UTXO,这样计算出用户的余额。
以太坊相比比特币,额外引入了账号状态数据,比如 nonce、余额 balance和合约数据,这些是区块链的关键数据,具有以下特性:
随着交易的入块要一直高效地更新,所有的这一些数据在不同节点之间能够高效地验证是一致的,状态数据一直更新的过程中,历史版本的数据数据需要保留。
系统中的每个节点执行完相同区块和交易后,那么这些节点中对应的所有账户数据都是一样的,账户列表相同,账户对应的余额等数据也相同。总的来说,这些账户数据就像状态机的状态,每个节点执行相同区块后,达到的状态应该是完全一致的。但是,这个状态并不是直接写到区块里面,因为这一些数据都是可以由区块和交易重新产生的,如果写到区块里面会增加区块的大小,加重区块同步的负担。
tansaction root: 跟比特币中的 Merkle Root作用相同,相当于区块中交易的指纹,用于快速验 证交易是否相同以及证明某个交易的存在。
state root: 这颗树是账户状态(余额和 nonce等)存放的地方,除此之外,还保存着 storage root,也就是合约数据保存的地方。receipts root:区块中合约相关的交易输出的事件。
在 Transaction Root中,用类似比特币的二进制 merkle tree是能够处理问题的,因为它更适用于处理队列数据,一旦建好就不再修改。但是对于 state tree,情况就复杂多了,本质上来说,状态数据更像一个 map,包含着账号和账号状态的映射关系。除此之外,state tree还需要经常更新,经常插入或者删除,这样重新计算 Root的性能就显得尤其重要。
Trie是一种字典树,用于存储文本字符,并利用了单词之间共享前缀的特点,所以也叫做前缀树。Trie树在有一些时候是比较浪费空间的,如下所示,即使这颗树只有两个词,如果这两个词很长,那么这颗树的节点也会变得很多,无论是对于存储还是对于 cpu来说都是不可接受的。如下所示:
相比 Trie树,Patricia Trie将那些公共的的路径压缩以节约空间和提高效率,如下所示:
1.密码学安全,每个节点都都是按 hash引用,hash用来在 LevelDb中找对应的存储数据;
c.扩展节点,跟叶子节点类似,不过值变成了指向别的节点的 hash,[key, hash]
d.分支节点,是一个长度为 17的列表,前 16元素为可能的十六进制字符,最后一个元素为 value(如果这是 path的终点的话)
在上图中的 trie包含了 4对 key value,必须要格外注意的是,key是按照 16进制来显示的,也就是 a7占用一个字节,11占用一个字节等等
1.第一层的 Node是扩展节点,4个 Key都有公有的前缀 a7,next node指向一个分支节点
2.第二层是一个分支节点,由于 key转换成了十六进制,每个 branch最多有 16个分支。下标也作为 path的一部分用于 path查找。比如说下标为 1的元素中指向最左边的叶子节点(key-end为 1355),到叶子节点就完成了 key搜索:扩展节点中 a7 + 分支节点下标 1 + 叶子节点 1355 = a711355
3.叶子节点和扩展节点的区分。正如上面提到的,叶子节点和扩展节点都是两个字段的节点,也就是 [key,value],存储中没有专门字段用来标识类型。为了区分这两种节点类型并节约空间,在 key中加入了 4bits(1 nibble)的 flags的前缀,用 flags的倒数第二低的位指示是叶子节点还是扩展节点。此外,加入了 4bits之后,key的长度还有可能不是偶数个 nibble(存储中只能按字节存储),为此,如果 key是奇数个 nibble,在 flags nibble之后再添加一个空的 nibble,并且用 flags的最低位表示是否有添加,详见上图左下角。
下面将通过代码片段的形式,逐一验证各个 trie的结构(前提是先在本地搭建起以太坊私有链)。
在 trie包中写单测函数,key为交易在区块中的 index,RLP编码,value为签名过的原始交易 RawTransaction:
如下合约,为了简单起见,合约中省去了构造函数等不相关的内容,部署后地址为:
运行输出以下数据 storedUint为 2018,跟合约里的数据是一致的。有必要注意一下的是 storedString的数据后面多了一个十六进制的 26(十进制为 38),是字符串长度 (19)的两倍,更多的细节请参见 。
同时,更复杂的数据结构如变长数组、map等规则会更为复杂,同时这里也忽略了一些字段打包存储等细节,但是都围绕着 storageTrie,基础原理没有改变。
易能链与海通安恒达成战略合作 共建大数据+区块链企业数字化资产评级及投融资平台
HUAWEI Pura X 新机首销,华为浏览器每日早报让资讯“说”给你听
技嘉Z890钛雕主板以DDR5-12762MHz登顶内存超频之巅 重写性能天花板